1. JOIN 개요
- 두 개 이상의 테이블들을 연결 또는 결합하여 데이터를 출력하는 것
- 관계형 데이터베이스의 가장 큰 장점이면서 대표적인 핵심 기능
- 일반적인 경우 행들은 기본키(PK)나 외래키(FK) 값의 연관에 의해 JOIN이 성립된다. 하지만 어떤 경우에는 이러한 관계가 없어도 논리적인 값들의 연관만으로 JOIN이 성립 가능하다.
# 주의할 점
- FROM 절에 여러 테이블이 나열되더라도 SQL에서 데이터를 처리할 때는 단 두 개의 집합 간에만 조인이 일어난다는 것이다.
- FROM 절에 A, B, C 테이블이 나열되었더라도 특정 2개의 테이블만 먼저 조인 처리되고, 2개의 테이블이 조인되어서 처리된 새로운 데이터 집합과 남은 한 개의 테이블이 다음 차례로 조인되는 것이다.
- 예를 들어 A, B, C, D 4개의 테이블을 조인하고자 할 경우 옵티마이저는 ( ( (A JOIN D) JOIN C) JOIN B)와 같이 순차적으로 조인을 처리하게 된다.
- 먼저 A와 D 테이블을 조인 처리하고, 그 결과 집합과 C 테이블을 다음 순서에 조인 처리하고, 마지막으로 3개의 테이블을 조인 처리한 집합과 B 테이블을 조인 수행하게 된다.
- 이때 테이블의 조인 순서는 옵티마이저에 의해서 결정되고 주요 튜닝 포인트가 된다.

2. EQUAL(등가) JOIN
- 두 개의 테이블 간에 컬럼 값들이 서로 정확하게 일치하는 경우에 사용되는 방법으로 대부분 PK ↔ FK의 관계를 기반으로 한다.
-그러나 일반적으로 테이블 설계 시에 나타난 PK ↔ FK의 관계를 이용하는 것이지 반드시 PK ↔ FK의 관계로만 EQUAL JOIN이 성립하는 것은 아니다.
- 이 기능은 계층형이나 망형 데이터베이스와 비교해서 관계형 데이터베이스의 큰 장점이다.
# 구문 형식

# ANSI/ISO SQL 표준 방식

# 예제

3. NON EQUAL(비등가) JOIN
- 두 개의 테이블 간에 컬럼 값들이 서로 정확하게 일치하지 않는 경우에 사용
- "=" 연산자가 아닌 다른(Between, >, >=, <. <= 등) 연산자들을 사용하여 JOIN을 수행하는 것
두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하지 않는 경우에는 EQUI JOIN 을 사용할 수 없다.
이런 경우 Non EQUI JOIN 을 시도할 수 있으나 데이터 모델에 따라서 Non EQUI JOIN 이 불가능한 경우도 있다.
# 예시
# 어떤 사원이 받고 있는 급여가 어느 등급에 속하는 등급인지 알고 싶다는 요구사항에 대한 Non EQUI JOIN의 사례
SELECT E.ENAME, E.JOB, E.SAL, S.GRADE
FROM EMP E, SALGRADE S
WHERE E.SAL BETWEEN S.LOSAL AND S.HISAL;
테이블 간의 관계를 설명하기 위해 먼저 사원(EMP) 테이블과 급여등급(SALGRADE) 테이블에 있는 데이터와 이들 간의 관계를 나타내는 [그림 Ⅱ-1-16]을 가지고 실제적인 데이터들이 어떻게 연결되는지 설명한다. 급여등급(SALGRADE) 테이블에는 5개의 급여등급이 존재한다고 가정한다.

사원(EMP) 테이블에서 사원들의 급여가 급여등급(SALGRADE) 테이블의 등급으로 표시되기 위해서는 “=” 연산자로 JOIN을 이용할 수가 없다. 그래서 사원들과 사원들의 급여가 급여등급 테이블의 어느 급여등급에 해당되는지 알아보기 위해서 사원 테이블에 들어 있는 데이터를 기준으로 급여등급 테이블의 어느 등급에 속하는지 1:1로 해당하는 값들을 나열해 보면 아래 [그림 Ⅱ-1-17]과 같이 바꿀 수 있다.
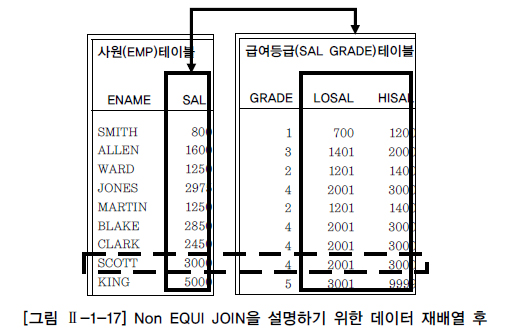
[그림 Ⅱ-1-17]을 보면 SCOTT라는 사원을 예로 들어 급여는 3,000달러($)이고, 3,000달러($)는 급여등급 테이블에서 2,001 ~ 3,000달러($) 사이의 4급에 해당하는 급여등급이라는 값을 얻을 수 있다.
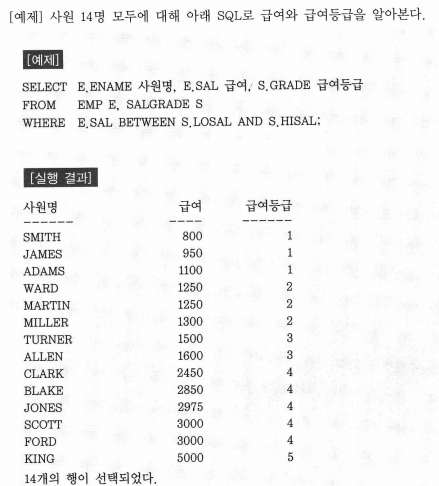
BETWEEN a AND b와 같은 SQL 연산자 뿐만 아니라 “=” 연산자가 아닌 “>”나 “<”와 같은 다른 연산자를 사용했을 경우에도 모두 Non EQUI JOIN에 해당한다. 데이터 모델에 따라서 Non EQUI JOIN이 불가능한 경우도 있다.
4. 3개 이상 TABLE JOIN
JOIN을 처음 설명할 때 나왔던 [그림 Ⅱ-1-12]를 보면서 세 개의 테이블에 대한 JOIN을 구현해 보도록 한다. [그림 Ⅱ-1-12]에서는 선수 테이블, 팀 테이블, 운동장 테이블을 예로 들었다. 선수들 별로 홈그라운드 경기장이 어디인지를 출력하고 싶다고 했을 때, 선수 테이블과 운동장 테이블이 서로 관계가 없으므로 중간에 팀 테이블이라는 서로 연관관계가 있는 테이블을 추가해서 세 개의 테이블을 JOIN 해야만 원하는 데이터를 얻을 수 있다.

지금까지 JOIN에 대한 기본적인 사용법을 확인해 보았는데, JOIN이 필요한 기본적인 이유는 정규화에서부터 출발한다.
정규화란 불필요한 데이터의 정합성을 확보하고 이상현상(Anomaly) 발생을 피하기 위해, 테이블을 분할하여 생성하는 것이다.
사실 데이터웨어하우스 모델처럼 하나의 테이블에 모든 데이터를 집중시켜놓고 그 테이블로부터 필요한 데이터를 조회할 수도 있다. 그러나 이렇게 됐을 경우, 가장 중요한 데이터의 정합성에 더 큰 비용을 지불해야 하며, 데이터를 추가, 삭제, 수정하는 작업 역시 상당한 노력이 요구될 것이다. 성능 측면에서도 간단한 데이터를 조회하는 경우에도 규모가 큰 테이블에서 필요한 데이터를 찾아야 하기 때문에 오히려 검색 속도가 떨어질 수도 있다. 테이블을 정규화하여 데이터를 분할하게 되면 위와 같은 문제는 자연스럽게 해결 된다. 그렇지만 특정 요구조건을 만족하는 데이터들을 분할된 테이블로부터 조회하기 위해서는 테이블 간에 논리적인 연관관계가 필요하고 그런 관계성을 통해서 다양한 데이터들을 출력할 수 있는 것이다. 그리고, 이런 논리적인 관계를 구체적으로 표현하는 것이 바로 SQL 문장의 JOIN 조건인 것이다. 관계형 데이터베이스의 큰 장점이면서, SQL 튜닝의 중요 대상이 되는 JOIN을 잘못 기술하게 되면 시스템 자원 부족이나 과다한 응답시간 지연을 발생시키는 중요 원인이 되므로 JOIN 조건은 신중하게 작성해야 한다.
'데이터베이스(DB) > SQLD' 카테고리의 다른 글
| [SQLD 2-2-1] SQL 활용 - 서브쿼리 (47) | 2024.05.23 |
|---|---|
| [SQLD 2-1-8] SQL 기본 - 표준 조인 (38) | 2024.05.23 |
| [SQLD 2-1-6] SQL 기본 - ORDER BY 절 (36) | 2024.05.19 |
| [SQLD 2-1-5] SQL 기본 - GROUP BY, HAVING 절 (39) | 2024.05.18 |
| [SQLD 2-1-4] SQL 기본 - WHERE 절 (34) | 2024.05.17 |



